আমি মাস কয়েক ধরে এই প্রশ্ন ছিল। দেখে মনে হচ্ছে আমরা কেবল চালাকি করে একটি আউটপুট ফাংশন হিসাবে সফটম্যাক্স অনুমান করেছি এবং তারপরে সফটম্যাক্সকে ইনপুটটিকে লগ-সম্ভাব্যতা হিসাবে ব্যাখ্যা করব। যেমনটি আপনি বলেছিলেন, সমস্ত আউটপুটগুলিকে তাদের যোগফলের মাধ্যমে ভাগ করে কেবল সাধারণ করা হয় না কেন? আমি উত্তর পাওয়া গভীর শিক্ষা বই বিভাগ 6.2.2 মধ্যে Goodfellow, Bengio এবং Courville (2016) দ্বারা।
ধরা যাক আমাদের শেষ লুকানো স্তরটি অ্যাক্টিভেশন হিসাবে z দেয়। তারপর সফটম্যাক্স হিসাবে সংজ্ঞায়িত করা হয়

খুব সংক্ষিপ্ত ব্যাখ্যা
সফটম্যাক্স ফাংশনটির এক্সপ ক্রস-এনট্রপি ক্ষতিতে লগটিকে মোটামুটি বাতিল করে দেয় যার ফলে ক্ষতিটি z_i তে প্রায় লিনিয়ার হতে পারে। এটি মোটামুটি ধ্রুবক গ্রেডিয়েন্টের দিকে নিয়ে যায়, যখন মডেলটি ভুল হয়, এটি নিজেকে দ্রুত সংশোধন করার অনুমতি দেয়। সুতরাং, একটি ভুল স্যাচুরেটেড সফটম্যাক্স অদৃশ্য গ্রেডিয়েন্টের কারণ হয় না।
সংক্ষিপ্ত বিবরণ
নিউরাল নেটওয়ার্ক প্রশিক্ষণের জন্য সর্বাধিক জনপ্রিয় পদ্ধতি হ'ল সর্বাধিক সম্ভাবনার অনুমান। আমরা প্যারামিটারগুলি থিটা এমনভাবে অনুমান করি যা প্রশিক্ষণের ডেটার সম্ভাবনা সর্বাধিক করে তোলে (আকারের এম)। যেহেতু পুরো প্রশিক্ষণ ডেটাসেটের সম্ভাবনা প্রতিটি নমুনার সম্ভাবনার একটি পণ্য , তাই ডেটাসেটের লগ-সম্ভাবনা সর্বাধিক করা সহজ এবং এইভাবে কে দ্বারা সূচিত প্রতিটি নমুনার লগ-সম্ভাবনার যোগফল:
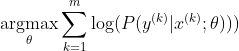
এখন, আমরা কেবল ইতিমধ্যে প্রদত্ত জেডের সাথে এখানে সফটম্যাক্সের উপর ফোকাস করি, যাতে আমরা প্রতিস্থাপন করতে পারি
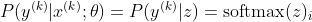
আমি kth নমুনার সঠিক শ্রেণি হিসাবে। এখন, আমরা দেখতে পাচ্ছি যে আমরা যখন নমুনা-ম্যাক্সের লগারিদম গ্রহণ করি, নমুনার লগ-সম্ভাবনা গণনা করার জন্য, আমরা পাই:
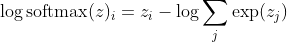
যা বড় আকারের পার্থক্যের জন্য প্রায় কাছাকাছি
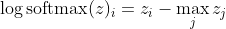
প্রথমে আমরা এখানে লিনিয়ার উপাদানটি z_i দেখতে পাচ্ছি। দ্বিতীয়ত, আমরা দুটি ক্ষেত্রে সর্বাধিক (জেড) এর আচরণ পরীক্ষা করতে পারি:
- যদি মডেলটি সঠিক হয় তবে সর্বাধিক (z) z_i হবে। সুতরাং, লগ-সম্ভাবনা asympotes শূন্য (অর্থাত্ 1 এর সম্ভাবনা) z_i এবং z এর অন্যান্য এন্ট্রিগুলির মধ্যে ক্রমবর্ধমান পার্থক্য সহ।
- যদি মডেলটি ভুল হয় তবে সর্বাধিক (z) অন্য কিছু z_j> z_i হবে। সুতরাং, z_i যোগ করা সম্পূর্ণরূপে -z_j বাতিল করে না এবং লগ-সম্ভাবনা মোটামুটি (z_i - z_j)। এটি লগ-সম্ভাবনা বাড়াতে মডেলকে কী করতে হবে তা স্পষ্টভাবে জানিয়েছে: z_i বৃদ্ধি এবং z_j হ্রাস করুন।
আমরা দেখতে পাই যে সামগ্রিক লগ-সম্ভাবনা নমুনাগুলির দ্বারা প্রাধান্য পাবে, যেখানে মডেলটি ভুল। এছাড়াও, এমনকি যদি মডেলটি সত্যই ভুল হয়, যা একটি স্যাচুরেটেড সফটম্যাক্সের দিকে পরিচালিত করে, ক্ষতি ফাংশনটি পরিপূর্ণ হয় না। এটি z_j এ প্রায় লিনিয়ার, এর অর্থ আমাদের প্রায় ধ্রুবক গ্রেডিয়েন্ট রয়েছে। এটি মডেলটিকে দ্রুত নিজেকে সংশোধন করতে দেয়। মনে রাখবেন যে উদাহরণস্বরূপ গড় স্কোয়ার ত্রুটির ক্ষেত্রে এটি নয়।
দীর্ঘ ব্যাখ্যা
যদি সফ্টম্যাক্সটি এখনও আপনার কাছে স্বেচ্ছাসেবী পছন্দ বলে মনে হয়, আপনি লজিস্টিক রিগ্রেশনটিতে সিগময়েড ব্যবহারের ন্যায্যতাটি একবার দেখে নিতে পারেন:
অন্য কিছুর পরিবর্তে সিগময়েড ফাংশন কেন?
সফটম্যাক্স হ'ল সিগময়েডকে সাধারণীকরণের মাধ্যমে বহু-শ্রেণীর সমস্যার জন্য সাধারণকরণ।



