আপনার মডেলের কর্মক্ষমতা সাধারণত বিভিন্ন পর্যায়ে ব্যবহৃত হয় তা মূল্যায়নের জন্য এগুলি দুটি আলাদা মেট্রিক।
আপনার মডেলটির জন্য "সেরা" পরামিতি মানগুলি (যেমন নিউরাল নেটওয়ার্কের ওজন) সন্ধানের জন্য প্রশিক্ষণ প্রক্রিয়ায় প্রায়শই ক্ষতি ব্যবহৃত হয়। আপনি ওজন আপডেট করে প্রশিক্ষণের ক্ষেত্রে এটিই অনুকূলিতকরণের চেষ্টা করছেন।
নির্ভুলতা প্রয়োগের দৃষ্টিকোণ থেকে আরও বেশি। উপরের অনুকূলিতকরণের প্যারামিটারগুলি একবার খুঁজে পাওয়ার পরে, আপনার মডেলের ভবিষ্যদ্বাণীটি সত্য ডেটার সাথে কীভাবে তুলনা করা যায় তা মূল্যায়নের জন্য আপনি এই ম্যাট্রিকগুলি ব্যবহার করেন।
আসুন একটি খেলনা শ্রেণিবদ্ধকরণ উদাহরণ ব্যবহার করুন। আপনি কারও ওজন এবং উচ্চতা থেকে লিঙ্গ সম্পর্কে ভবিষ্যদ্বাণী করতে চান। আপনার কাছে 3 টি ডেটা রয়েছে, সেগুলি নিম্নরূপ: (0 টি পুরুষের জন্য, 1 জন মহিলা হিসাবে)
y1 = 0, x1_w = 50 কেজি, এক্স 2_ ঘন্টা = 160 সেমি;
y2 = 0, x2_w = 60 কেজি, এক্স 2_এইচ = 170 সেমি;
y3 = 1, x3_w = 55 কেজি, এক্স 3_ ঘন্টা = 175 সেমি;
আপনি একটি সাধারণ লজিস্টিক রিগ্রেশন মডেল ব্যবহার করেন যা y = 1 / (1 + এক্সপ্রেস- (বি 1 * x_w + বি 2 * x_h))
আপনি কীভাবে বি 1 এবং বি 2 খুঁজে পাবেন? আপনি প্রথমে ক্ষতির সংজ্ঞা দিন এবং বি 1 এবং বি 2 আপডেট করে পুনরুক্তি পদ্ধতিতে ক্ষতি হ্রাস করতে অপ্টিমাইজেশন পদ্ধতি ব্যবহার করেন।
আমাদের উদাহরণস্বরূপ, এই বাইনারি শ্রেণিবদ্ধকরণ সমস্যার জন্য একটি সাধারণ ক্ষতি হতে পারে: (সামিট চিহ্নের সামনে একটি বিয়োগ চিহ্ন যোগ করা উচিত)

আমরা জানি না বি 1 এবং বি 2 কী হওয়া উচিত। আসুন আমরা এলোমেলো অনুমান করি বি 1 = 0.1 এবং বি 2 = -0.03 বলি। তাহলে এখন আমাদের ক্ষতি কী?
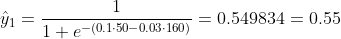
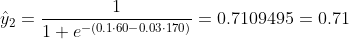
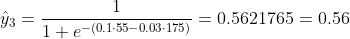
সুতরাং ক্ষতি হয়
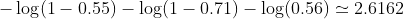
তারপরে আপনি অ্যালগরিদম শিখবেন (যেমন গ্রেডিয়েন্ট বংশদ্ভূত) ক্ষতি হ্রাস করতে বি 1 এবং বি 2 আপডেট করার একটি উপায় খুঁজে পাবেন।
বি 1 = 0.1 এবং বি 2 = -0.03 যদি চূড়ান্ত বি 1 এবং বি 2 (গ্রেডিয়েন্ট বংশোদ্ভূত উত্স থেকে আউটপুট) হয় তবে এখন সঠিকতা কত?
আসুন ধরে নেওয়া যাক y_hat> = 0.5, আমরা আমাদের ভবিষ্যদ্বাণীটি মহিলা (1) স্থির করি। অন্যথায় এটি 0 হবে Therefore সুতরাং, আমাদের অ্যালগরিদম y1 = 1, y2 = 1 এবং y3 = 1 পূর্বাভাস দেয় আমাদের যথার্থতা কী? আমরা y1 এবং y2 এর উপর ভুল ভবিষ্যদ্বাণী করি এবং y3 এর সাথে সঠিক একটি করি। সুতরাং এখন আমাদের নির্ভুলতা 1/3 = 33.33%
পিএস: আমিরের উত্তরে ব্যাক-প্রচারকে এনএন-তে একটি অপ্টিমাইজেশন পদ্ধতি বলা হয়। আমি মনে করি এটি এনএন এর ওজনের জন্য গ্রেডিয়েন্ট সন্ধান করার একটি উপায় হিসাবে বিবেচিত হবে। এনএন-তে সাধারণ অপ্টিমাইজেশন পদ্ধতি হ'ল গ্রেডিয়েন্টডেসেন্ট এবং অ্যাডাম।
